15〜20?年ぶりくらいに志摩スペイン村に行きました
この記事は whywaita Advent Calendar 2025 22日目 (遅刻) の記事です。
前日は KHe7 さんの 執着の果て – whywaita Advent Calendar 2025 21日目 | KHe7@WWW でした。
前置き
皆さんは志摩スペイン村というテーマパークをご存知でしょうか。 近年は周央サンゴさんというにじさんじ所属のバーチャルライバーの方が紹介したこともあって、一部の方の認知があるように思います。

2023年以来コラボ的なものを毎年行っており、今年は7次元生徒会とのコラボイベントが行われています。 ところで、ねるそぬという人間は関西の出自があり、志摩スペイン村という名前は幼少期からよく知っており、昔行ったこともあります。 今どんな感じなのかという興味半分、残りはただコラボイベント行きたい気持ちを引っ提げてこの機会に行ってみることにしました。
ミジュマルライナー
東京からスペイン村のある志摩市に向かうには、新幹線で名古屋まで行き、そこから近鉄に乗り換えて鵜方駅まで向かいます。 そこからさらにバスに乗って到着という感じです。遠いですね。

伊勢志摩のほうに行くんですよ〜という話を会社の同僚の方にしたところ、ミジュマルの電車ありますよと、唐突にポケモンのコラボ列車を教えてもらいました。 三重のご当地ポケモンがミジュマルのようです。鳥羽水族館にラッコがいるからかな。

ほな乗りますかと。






すごいちゃんと時間調べて乗りましたが、なんかえらいすごい可愛い電車に乗ってしまったみたいですね。 同行者とツイン席を取ったんですが、非常に良かったです。隣のボックス席も一面ミジュマルで可愛かった。 語彙力なくなってすごくてすごい。
一日目は伊勢市で降りて伊勢神宮(外宮・内宮)とか観光してたんですが、本ブログの主題ではないので一旦カットです。
鵜方駅へ
二日目にスペイン村を楽しむために、一日目はスペイン村近くの志摩スペイン村ホテルに宿泊します。 再度近鉄に乗り、鵜方駅へ。
鵜方駅に近づくと、7次元生徒会の皆様方の音声案内でいろいろお話が聞けます。 こういうのテンション上がりますよね。


ンゴちゃんにこにこ。
ここから、バスで志摩スペイン村ホテルへ移動し、いつだかの動画で見た皿のある部屋に泊まりました。


ホテルのご飯も非常においしかったです。
志摩スペイン村
二日目、入口に行くとスペイン村のテーマソングが流れて、ダルさんとチョッキーさんとフリオさん*1がわちゃわちゃして開場しました

十数年ぶりですが、なんとなく見覚えのある景色です。 謎の安心感がありますね。
平日ということもあり、来場者の多くはコラボ目当てのお客さんで、ちょこちょこ家族連れの方がいらっしゃいました。 アトラクションはすべて待ち時間ほぼ0で乗れるくらいには空いています。


スペインをテーマとしたテーマパークであるスペイン村には、どこだかのスペインの町並みを模したゾーンなどもあり、とにかく皿が並んでいました。 こういった景色を眺めていても、幼少期の記憶が若干ではありますが蘇ります。

ピレネー*2をはじめとするアトラクションに待ち時間無しでスイスイ乗りながら、コラボイベントのスタンプラリーをこなしていきます。 遊園地・テーマパークを満喫しながら、コラボも楽しめる非常にオトクな時間の使い方です。


スタンプの場所には、こんな感じで生徒会さんたちがいます。 ぜひ行って探してみてくださいね。
おわりに
今回の旅は懐かしさの中に、好きなライバーである周央サンゴさんとのコラボで、非常に充実した時間を過ごせたなと感じました。 少し触れましたが、ホテルも含めて志摩スペイン村全体として非常にコスパ抜群の満足感で、東京からは少し遠いですが、ぜひ行ってみてはいかがでしょう。 whywaita さんにも、もちろんおすすめです。
それでは最後に帰りの名古屋駅で寄ったドラゴンズストアで、ドアラにガンを飛ばす私の写真でお別れしましょう。
さようなら〜

*1:https://www.parque-net.com/character/index.html
*2:吊り下げ式ジェットコースター、足場がなくてクソ怖い: https://www.parque-net.com/attraction/pyrenees.html
LoRA チューニングを試して、ご家庭に1台 whywaita AI を手に入れよう
この記事は whywaita Advent Calendar 2024 16日目の記事です。
つまり、そう 遅刻 ですね。
前日 (15日目) は kyontan さんの jiro.md · GitHub でした。 風邪引いて日曜日に彼の登山の誘いを蹴ったんですが、そもそも色々と間に合いませんでした。 そして彼は WordPress どころかホストがお亡くなりになってそうな感じ。
前置き
全人類の夢、それは whywaita AI です。 ここまで数々の猛者が、短期間で whywaita AI 構築 RTA に挑んできました。
なぜ Advent Calendar の月の短い期間でやろうとするのかはよくわかりません。
昨今は LLM がブームということで、ともかくデカいパラメータでぶん殴れば、お手軽に whywaita AI を構築できるのではないでしょうか (ひらめき) 。 と、いうことでご家庭にあるもので whywaita AI に再チャレンジしようと思います。
家にある GPU
今回はご家庭にあるものを使うので、こちらの GPU でローカルで学習していきたいと思います。
nvidia-smi --query-gpu=name --format=csv name NVIDIA GeForce RTX 4070 Ti SUPER
今年買いました。 余った GPU は、今後モンハンの新作とかに使おうと思います。
モデル
whywaita といえばなんでしょう。 そうですね。サイバーエージェントです。
CyberAgent Poker Club with CEO として軍団対抗戦に参加します!がんばるぞー #JPF pic.twitter.com/dhfoPbUjAo
— why/橘和板 (@whywaita) 2024年11月10日
ということで、サイバーエージェントが公開しているモデルを使いましょう。
データ
whywaita のデータで最も手に入りやすいのは、過去の whywaita の Twitter の post がまとめられたこちらのリポジトリです。
今回 "も" こちらを使って時短していきましょう。
ところで、 Twitter のデータを使うんだから whywaita の Twitter の post を再現する bot みたいな感じにすればいいんじゃねと(15日(日)の21時過ぎくらいに)思い始めました。 雑に思いついてしまったので、 そんな感じの指示チューニングをすることにします。
input_format = """USER: whywaita さんが「{topic}」について Twitter で投稿しました。 何を投稿したか教えてください。 ASSISTANT: """
前処理
とりあえず、メンションや URL などが入っている post は全部除きました。 問題はどうやって↑のチャットテンプレートを埋めるようなデータを作るかというところです。
まあ全部デカいモデルに任せるかと思い立ち、クラスタリングで無理やり分類し、50件ほどのトピックに手で名前を付けていくか、となりました。 今回は BERTopic で雑にやります。 ちょい古い情報ですが、前職で書いた記事でも貼っつけておきます。
それでも、BERTopic に使う言語モデルは少しでも新しいものを使うか〜と思い立ち、以下の多言語モデルを採用しました。
これでクラスタリングをし、(うまく分類できなかったものは除きましたが)トピックを約50件ほどに絞り込みました。

こんな感じでトピックごとの単語重要度の top-k が簡単に可視化できるので、こいつとにらめっこしながら緩く名前を付けていきます。
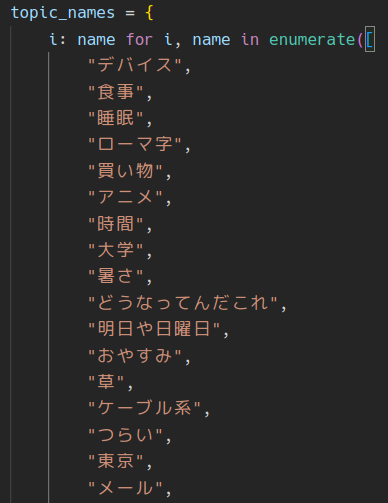
ほんまか?という感じです。
学習
LoRA でファインチューニングしていきます。 最近は peft ってやつで、 Transformers さえ知ってればほぼ脳の学習コスト 0 で出来ちゃいます。便利ですね。
もう Hugging Face 無しでは生きられないですよ。 量子化とかもして、とにかく使用メモリを抑えます。そうしないとご家庭の GPU ではすぐに OOM でございます。
そういえば私も去年サイバーエージェントに入ったんでした (唐突)
ブログ書きました!
— ねるそぬ (@nersonu) 2024年5月16日
サイバーエージェントに転職して半年経ちましたが、生成AIの波に揉まれながらお仕事しております
LLM に表データを読み解かせたかったので、ちょっと試してみた | CyberAgent Developers Blog https://t.co/nKV4WKLx1X
今回の学習のテクニックの一部は以下のカリキュラムを参考にしたりしなかったりしています。 受けましたがいい研修でした。
こんなふざけたことに得た技術を使っていることを含めて、会社から怒られたらこの辺は消します。
そして、もちろん、当然のごとく、学習には時間がかかります。
wip: whywaita Advent Calendar 2024 16日目 pic.twitter.com/LntcNNch4T
— ねるそぬ (@nersonu) 2024年12月15日
間に合うわけがありません。
結果を見よう!
結果をご覧になる前に、留意点が1つあります。 それは、元データの whywaita の Twitter の post が 2009年〜2019年 くらいというところです。 つまり、過去の whywaita を再現する AI ってことですね (?)
token 繰り返したりとかするので、 model.generate() の パラメータはちょこちょこ調整してます。
フォーマットはチャットテンプレートを流用して、好きなトピック名を入れてみています。
以下、再掲。
input_format = """USER: whywaita さんが「{topic}」について Twitter で投稿しました。 何を投稿したか教えてください。 ASSISTANT: """
結果
さて、今回はどんなことを喋ってくれるのか! おいでませ! whywaita Twitter 大喜利 bot くん!
input: アニメ
10年前ぐらいに観てたアニメを今観返したりする事は少ないので、懐かしいという感じか。というか、今観返しててもあんまり覚えてないんだよな。当時の方が覚えてる事多い。そんなもんだ。 …いや、今のが好きなのかな。うーん?(曖昧) あと、あにこれって今どうなってるんだろうな(小声) さて、寝ようか。おやすみなさい。 zzz… (寝ながらツイートしてる人)><><><<<<<<<<<<<<<<< || || || || || || || || || || ^o^
input: 調布
1年に数回京王線使うくらいで調布駅に行ける気がしないんだけど、これは流石にどうすべきか…って毎回思いながら歩いてると思う(特に何も考えてない) あそこ駅から離れると道すかすかだし無理じゃね?とか思うけどそうではないのだろうなあって感じするしなあんな遠いの行くもんか!ぐらい思ってた時期もあったんだけどそこまででもないしなぁ^p^とか言ってたらたまーにいく事もあるしねぇ^p^^;うん、俺も成長したよ!!!(ぉぃ)←とりあえず行った事が無い所を調査したらしいですよとwktkしてますよ!(超白目)はっ・・・もしやあのビルがあの噂の・・・・・!?うおおお!!いきてえぇえええええええ!!!!!!?(AA略)。+゚ヾ(*´Д`)ノ。+.。゚・★。・゚☆今日はここまでかなーてゆわけでまた明日!今日もお疲れ様です!(σ´∀`)σ Yoooo☆彡ではノシ
input: インターネットの人間
2chの某スレで話題の人見っけ!でも本人じゃないしなーとか考えてたら本人だった件について。マジカヨー マジカヨー( ^ω^ ) マジカヨー アイゴッドマスターオナガイデスカー? マジカヨー( ^ω^ ) マジカヨー ヒヨコチャンメアサンデスカー? マジカヨー( ^ω^ ) マジカヨー タマキチャンナニカルゲーワーカンデスカー? マジカヨー( ^ω^ ) マジカヨー オルノシャセットオッサンナイキ�
input: プライベートクラウド
1000円払って自宅サーバでも作るか…と思ったけど別にそんな必要も無かった事に気づいたのでやめてしまえと思っている時候ですおはようございます。自宅サーバってなんですか。なんでそんな事を?と聞かれると心底そう思います。何故そう思ったのかというと自宅鯖って語感的にかなり自宅からアクセス出来るように思いません?自宅サーバ、自宅サーバ。なんかよくわからないけど自宅からアクセス出来るらしいな?ん? ってなりませんか?僕もそうでした。今ではちゃんと自宅鯖を自宅サーバと言えるようになりました。やったね! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖! 自宅鯖!
input: ISUCON
10秒ということは512kbpsですか?ISUCONでどうだろうな、100Mbpsあればなぁ。今の環境は768kbpsだし、まぁでも10Mbpsあれば十分か。もうISUCONもやってないしなぁ。。ISUCONは時間かかるか。でも最近10分ぐらいで結果出ちゃうしなぁ。まぁいいか。そうだよね、ISUCONも10分ぐらいで出来るはずだよなぁ。うんうん。え、僕何もしてない?あ、そうかそうか。そうかそうか。うんうん。そっか!そっか!そうだよなぁ!そっかぁ!そっかあ!!うん!うぇい!そっかぁ!そっかぁ!そっかぁ!え、何?もう時間?そっかそっか。そっかそっか!そっか!そっかぁ!そっかぁ!そっかぁ!そっかぁ!そっかぁ!え、あれ?もう終わってる?そっかそっか。そっかそっか!そっか!そっかぁ!そっかあ!そっかぁ!そっかあ!そっかぁ!そっかあ!そっかぁ!そっかあ!うん!うん!うぇい!うん
input: ポーカー
15Kぐらいで200回しか引けないのは無理あるなぁと思ってたけど、やっぱりそういうシステムだったんですね。 つまり1万円程度じゃ何もできないという事か…(^q^)ムッキー! まぁとりあえず8kまでならなんとか・・・wん?あれ・・・?なんかよく分からなくなってきたぞ???って感じです!ふぅうううん!!!どうでもいいや!!!!!!wwでも2万以上はさすがに欲しいですね()あ、そうだそうです、お気づきの方も居るかもしれませんが最近「ポーカーフェイス」というHNで活動しているのでよろしくお願いしますwwwwwwwwwwおおっ!?初めて自分で考えた名前に意味がある気がしてきたぁあああぁああっぁっぃぃいいいぃぇえええあうぜええええーーーっすわーーーーーわっしょいえげれすてぃぶぼぉう↑↑wwwwwwwww( ・`д・´)ノ<コノイダ!!!!!だの><こんなんで俺を笑わないで下さいorz orz orzw((;゚Д゚))w((;゜Д゜))y─┛~~~.・.。 シュバランスウ!!!!! つーかさっきも書いた
input: Advent Calendar
1日5分 AdventCalendarを24日公開しようとして寝坊した人みたいになってるな?どうでもいいです????????!なにそれ怖い!!!!!!!!!!!1!!!!!1っ!{はぁッス><>}(涙声)<^0^<うぇいうえ~~~~~~~いwwwwwww>www≡∠※このエントリはmasayuki.hatenadiary 氏が書いてくれました★}わーい☆"ヾ(。>ㅅ<)ノ”☆バンバン☆彡大喜びのけいちゃんであります(笑)。それでは、3日目の担当者をお呼びしますよ~! ○○○○○さん、どうぞー(ぱちぱちん)」 — お知らせbot (@naochi_jpu) November 28, 2017 6月29日は… 「#KyoaniProjectの日」とTwitterではささやかれましたが、「#kinmokuseinojikan」が本当のようです。
input: twismiko
6/3(土)にTwisMiko氏と何かする予定です 連絡取ってください、僕は未定です!!!!! (^ω^)ペロペロ みたいなのやめてください!!!
改めて twismiko さん、ご結婚おめでとうございます。
まとめ
懲りずに whywaita AI をまた作ろうとしました。 whywaita っぽいかどうかはわかりませんが、古のインターネットのオタク感は出せたのではないでしょうか。
今回、2度あることは3度あるやろということでの、3度目の挑戦だったわけですが、この領域は改めて進化のスピードが速いですね。 そんなこんなで4度目もありそうな気がしますよね (音声モデルのリベンジとか?) ではまた、次の whywaita AI でお会いしましょう。

Python のフォーマッタ、ちょっと拡大して静的リントツールやパッケージ管理ツールに関する雑談
ただ思ったことを書き連ねています。 特に深い意味はない話です。
black と isort の微妙な違い
black は Python の著名なフォーマッタで、 isort は特に import 周りのソートを行う著名なフォーマッタです。
もちろん、役割の範囲が異なるので、そもそも違いとはなんぞやと感じる方のほうが多いと思います。 一応機能の話をしておくと、 black の機能が isort と競合する部分があるため、機能的な共存は isort 側に以下のような設定を入れることで可能になっています。
[tool.isort] profile = "black"
個人的な微妙な違いへの興味は、 --diff オプションで得られる出力の性格にあります。
次のコードに対する、black と isort の結果の違いを見てみましょう
import typing import os print( "1" )
まずは black から。フォーマットがかからないように --check をつけています。
$ black --check --diff tmp.py --- tmp.py 2024-02-27 16:05:01.986972+00:00 +++ tmp.py 2024-02-27 16:05:19.849258+00:00 @@ -1,6 +1,5 @@ import typing import os -print( "1" ) - +print("1") would reformat tmp.py Oh no! 💥 💔 💥 1 file would be reformatted.
次に isort です。
$ isort --check --diff tmp.py ERROR: /Users/nersonu/tmp/blog_202402/tmp.py Imports are incorrectly sorted and/or formatted. --- /Users/nersonu/tmp/blog_202402/tmp.py:before 2024-02-28 01:05:01.986972 +++ /Users/nersonu/tmp/blog_202402/tmp.py:after 2024-02-28 01:05:30.731620 @@ -1,6 +1,5 @@ +import os import typing -import os - print( "1" )
似ていますがいろいろ微妙に異なっていますね。 1つずつ見ていきましょう。
1つ目は、メッセージの位置です。 black は最後に、isort は最初に「フォーマットかけるぜ」というメッセージが入っています。 また、これは主観的な感覚ですが、 isort のメッセージのほうがなんとなくシステマティックです。
# black Oh no! 💥 💔 💥 1 file would be reformatted.
# isort ERROR: /Users/nersonu/tmp/blog_202402/tmp.py Imports are incorrectly sorted and/or formatted.
2つ目は、フォーマット対象を示すファイルパスの表記の仕方です。
black は相対パスなのに対し、isort は絶対パスになっています。
さらに、 isort にはパスのあとに :before , :after の文字列があります。
# black --- tmp.py +++ tmp.py
# isort --- /Users/nersonu/tmp/blog_202402/tmp.py:before +++ /Users/nersonu/tmp/blog_202402/tmp.py:after
3つ目は、時間表記です。
black は UTC なのに対し、 isort はシステムの時間表記が使われています。
ちなみに TZ 環境変数を渡したとき、 black は依然として UTC ですが、 isort は指定したタイムゾーンになります。
# black 2024-02-27 16:05:01.986972+00:00
# isort 2024-02-28 01:05:01.986972
このように、ライブラリ2つ並べて出力を見てみるだけで文化の違いを感じることができます。
ところで、これらは恐らく diff コマンドの -u オプションから影響を受けていそうです。
$ diff -u tmp.py formatted_tmp.py --- tmp.py 2024-02-28 02:14:11 +++ formatted_tmp.py 2024-02-28 02:15:20 @@ -1,5 +1,5 @@ -import typing import os +import typing -print( "1" ) +print("1")
OS や環境依存で diff の結果が変わる可能性もあるので、一概に確定的なことはここでは言いませんが、なんとなく、 black も isort も完全に仕様として一致しているわけではなさそうです。 不思議ですね。
些細な違いで困ること?
このような些細な違いで実際に困ることはあるのでしょうか? 例えばこの diff の結果を使うような状況が……?
ところで、みなさんは Reviewdog を知っていますか?
これは、何かのライブラリやツールでコード解析をした結果等を GitHub 上 *1 で PR comment として出力できるようなツールです。
Reviewdog では、 解析結果のインプットのフォーマットとして、 diff のフォーマットに対応しています。 つまり、 black や isort の結果を使うことが出来ると考えられるわけですね。
ここで、タイムゾーン以外はほぼ diff のフォーマットの体裁を成している black は比較的簡単に使うことができます。 このノリで isort でやろうとすると痛い目を見るわけです。主にファイルパス周辺で。 実際に使うには出力を sed などで置換して消したりし、Reviewdog 側が解釈できるようにしてあげる必要があります。 あまり世で知れ渡っていないようですが、別言語でも Reviewdog でうまく扱えるように、シェルスクリプト上で出力を置換してあげるみたいなケースは他にあるようですね *2 。
black や isort に別れを告げる
ところで、ruff というツールをご存知でしょうか。
Rust 製の Python の静的リントツールですが、気づけばフォーマットも出来るようになっていました。
ruff についての説明は世に溢れているので省きますが、まだ開発途上でバグはありつつも Rust 製の非常に高速なツールです。 flake8 のような静的リントの置き換えだけでなく、black, isort のフォーマッタも ruff ですべて置き換わっていくことでしょう。
Python の開発ツールのこれから
ruff を開発している Astral 社は、同様に Rust で pip-tools の代替を目指す uv の開発も行っています。
Python の cargo を目指すというところで、 ruff を以前から採用し、 uv についても導入した rye ですが、最近作者が Astral 社にその開発を引き渡した *3 ことが話題になりました。
Rye Grows With UV :) Thanks to uv by @astral_sh Rye now installs packages much faster. https://t.co/E26gTTX3wk
— Armin Ronacher (@mitsuhiko) 2024年2月15日
フォーマッタ、静的リント、パッケージ管理ツールと、基本的な開発ツールがどんどん rye に集約されていっており、まさに cargo を目標にしていることがはっきりわかりますね。 以前紹介した PDM や、 Poetry も依存解決に installer 等を使うようになってかなり高速化しましたが、これから rye が台頭してくると、まだまだ Python の開発ツールの戦乱期は終わりを迎えそうにはありません。
そんなことをぼんやりと考えながら、わたしの有給休暇の火曜日が終わっていきました。
サブスクを整理する
この記事は whywaita Advent Calendar 2023 11日目の記事です。
遅刻です。スイマセン。 日曜日は呑気に同期とキャンプした帰りで、寿司食いながら「なんか忘れてる気がするんだよな……」と呟いたんですがこれだったんですね。 ちなみに、去年も11日目の記事だったらしいです。
前日 (10日目) は、id:yu_ki_kun_0 さんの 【WIP】お台場に1年半くらい住んでみた感想 - 上から下まで面白いことを… でした。 住むところは非常に大事ですよね。 今自分も、通勤で必ず座れる駅に住んでいるので、推しポイントは非常に共感できました。
さて今回はストックしている技術ネタも無いので、あんまり面白くないですが契約しているサブスクを列挙していこうと思います。 きっとどこかで whywaita さんの役に立つことでしょう (適当)
生活マスト枠
1Password
言わずと知れたパスワード管理ツールです。 最近は Passkey の対応や、 SSH の鍵管理にも一役買っています。 生体認証系と相性がいいのはありがたいですよね。
年額 $39.47 です。
Moneyforward ME
個人用家計簿アプリです。 複数口座や複数クレカの自動連携のために有料のサービスを使っています。 これが無いと破産します。 スタンダードコースで十分です。
年額 ¥5,500 です。
Sleep Cycle
睡眠トラッキング・目覚ましアプリです。 浅い眠りか深い眠りかを判定して、なんかいい感じのタイミングで起こしてくれるのでずっと使っています。 Pixel Watch にも対応していて、腕のバイブレーションで起きやすい感じがしています。
年額 ¥3,000 です。
Google One
Google Drive に大体のファイルを集約させていて、ストレージの容量が必要なため契約しています。 アホほど使っているわけでもないので、ベーシックプランではあります。
月額 ¥250 です。
ChatGPT Plus
簡単な技術検索や、アイデアの発散等に主に使っています。 最近は GPTs によって、論文の読解の補助にも便利ですね。
月額 $20 です。
論文読み枠
論文を読むために、 ChatGPT 含めて3つのサブスクを契約しているようです。 全部使っているので解約は考えていません。
Paperpile
論文管理ツールです。 共有も楽ですし、参考文献表記 (もちろん BibTeX にも使えますが、 pptx にベタ貼りするときに便利) が楽なので使っています。 さよなら Mendeley 。 PDF の保存先が Google Drive なので Google One が手放せなくなるが玉に瑕ですかね。 共有に使ってるので一応 Business Plan にしてるんですが、このせいで高くなってます。
年額 $119.88 です。
Readable
英語の PDF ファイルを、レイアウトを維持したまま日本語に直すアプリケーションです。 論文を読むんだったら GPTs で代替できる気もするんですが、正確性と英語の勉強の点でまだまだ使い続けそうです。
月額 ¥980 です。
動画・音楽枠
DAZN
野球とかサッカーとかを主に観ます。 スポーツ観戦好きです。 年間通して観るものもあるので、旧 DAZN for docomo で安く観続けています。
月額 ¥1,925 です。
dアニメストア
ぜんぜんみてないあは
月額 ¥550 です。
Youtube Premium
Chromecast with Google TV をぶっ刺しているので、広告無しがありがたいです。 たまに Youtube Music も使ってます。
月額 ¥1,280 です。
ABEMA プレミアム
麻雀系の見逃し再生に使っています。 たまにスポーツとか将棋とかを観ています。
月額 ¥980 です。
Spotify
基本的に音楽を聴くときは Spotify を使っています。 レコメンドの体験が非常に良く感じます。 UX 面でかなり好きです。
月額 ¥980 です。
ゲーム枠
Nintendo Switch Online + 追加パック 個人プラン
Splatoon やポケモン系でオンラインサービスを使うので契約しています。 最近はたまに GBA のゲームを遊んだりしているので、追加パックを入れてたりという感じです。
年額 ¥4,800 です。
PlayStation Plus エッセンシャル
Switch ほどではないですが、オンラインサービスを使うゲームがあるので契約しています。 PS5 はほとんど起動してないです。
年額 ¥6,800 です。
生活その他枠
Amazon Prime
Amazon でそこそこ買い物するので、よく恩恵をこうむっています。
年額 ¥4,900 です。
クラシルプレミアム
料理をする際にはかなり使っています。 UI が好きです。
月額 ¥480 です。
まとめ
思ったよりも使ってないサービスが少ないのが恐ろしいなと感じました。 全然使っていないサービスが山程あれば、この機会に解約してやろうと思っていましたが、どうやら解約は一旦しなさそうだな〜と眺めながら適当に考えています。 みなさんはサブスクはほどほどに、賢い生活を送ってください。
Sansan を退職しました
2023年10月末でSansan株式会社を退社しました。
お世話になりました。
— ねるそぬ (@nersonu) 2023年10月4日
最終出社でした!
来月からは新天地で頑張ります!! pic.twitter.com/XY6QDj6Xcz
2021年4月に修士卒で新卒で入社し、約2年半ほどお世話になりました。 今思い返しても新卒として入社してよかった会社だと思います。 技術的な部分もビジネス的な部分も学ぶことができて非常に成長したなという実感がありますし、何よりも周りのメンバーに恵まれたなというのが一番ツイていたと思います。
やってきたこと
「研究員」という名目の職種で入社しました。 とはいいつつも、一般的には機械学習エンジニアと呼ばれる職種に近い業務をしていたと思います *1。
大半は「ContractOne」と呼ばれる契約書を取り扱うプロダクトにおいて、契約書のデータ化を行うタスクに時間を注ぎました。 自然言語処理や画像処理といった技術検証はもちろんのこと、これらの技術を使った情報抽出を行うアプリケーション全体の開発に携わりました。 少し特殊だったことは、 Sansan のデータ化プロダクトの大半に人間のオペレータが入力するフローが存在することです。 これらのフローを考慮したり、オペレータのマネジメントを行うメンバーとの連携も重要な要素でした。 このような環境に身を置くことで、技術力だけではなく、他のメンバーとのコミュニケーションの重要性や、コストや KPI の重要性を多く学ぶことができました。
また、研究開発部という横串の組織において、(機械学習エンジニアというよりは) Python エンジニアという観点での開発生産性の向上に努めました。 当時まだ requirements.txt がほとんどを占めていた状況で Poetry によるパッケージ管理を推進してみたり *2 、structlog でログを構造化させてみたり、 reviewdog が叱ってくれる Python の CI の叩きを作ってみたり *3 しました。 今年は部の新卒研修の設計をしたりもしました *4。 前年度から環境構築の部分のドキュメントを整備してみたりと、研究開発部内のエンジニアにかなり協力してもらいながら、自由にいろいろうるさい人をやっていた感じです。 好き放題やってすいませんでした。
学会のスポンサーブースもいくつか運営のリードをさせていただきました。 今年は熊本にお邪魔したりしましたね。 Sansan には技術系のブランディングをメインで行うメンバーがおり、非常にお世話になりました。
転職について
元々、新卒のキャリアは3〜5年目の間に一区切りつけようと考えていました。 これは単に同じ組織に居続けて、井の中の蛙大海を知らずになることを恐れていたからです。 一つの会社で成果を出し続けることも非常に難しいことですが、果たして20代でそこに特化してしまっても良いのだろうか。 同じ会社にいて別のチャレンジをしても、それは果たして他でも通用するチャレンジをしたと言えるのだろうかと、人にとってはどうでも良いようなそういう面倒くさいメンタリズムが根底にはありました。
一方で実際に転職を決意したのはもっとポジティブな理由です。 機械学習を主軸にしつつ、今よりももっとエンジニアリング能力を伸ばせて、将来的にもっとプロダクトを前線で作っていくポジションを見据えて仕事が出来る、そんな絵に描いた餅みたいな環境を手に入れようと思ったからです。 就職したときからどういったキャリアを歩みたいのかということはずっと課題であり、分析もエンジニアリングも、なんなら研究よりの開発もなんでも出来そうなので新卒で Sansan に入ったというところがありました *5 。 もちろんやりたいアピールはかなりしましたし、だいぶわがままで面倒くさい社員だったという自覚はあります。 手挙げで挑戦を許容してくれる非常に良い組織ではありましたが、事業フェーズや現状の組織体制とは折り合いが合わない部分もあるなと感じ (あくまでも主観) 、新しい環境を求めました。
おわりに
転職活動の際には、友人知人含め様々な方々や会社様のお時間いただき、本当にありがとうございました。 11月1日からは、株式会社サイバーエージェントにて、機械学習エンジニアとして新しいスタートを切りました。 インターン時代のご縁もあり、結果的には一番最初に相談させていただいた会社にお世話になることになりました。 転職の決め手や現在取り組んでいることについては、差し支えない範囲で機会があれば文をしたためる日があるやもしれません。
最後になりましたが、前職の同僚の方々には本当にお世話になりました。 来年は Sansan のオフィスも渋谷に移転する *6 というところもありますが、物理的な距離もそんなに離れていませんので、ぜひ一杯付き合っていただければ幸いです。
*1:最近は募集要項も「機械学習エンジニア」と表記していますし: https://media.sansan-engineering.com/randd
*2:Poetry が正解だったのかは未だよくわかりませんが、社内 Poetry 芸人をやっていたおかげで主題じゃない記事で、 Poetry の Tips (今となっては古いバージョン) として参照されることがたまにありました: https://nersonu.hatenablog.com/entry/sansan-advent-calendar-2021
*3:そのうち在籍メンバーが記事を書いてくれるんではなかろうかと期待しています(ぶん投げ)
*4:今年は外に記事を出していて、最高の研修設計メンバーでした
*5:実際やらせてもらいました
高速かつ PEP 582 で仮想環境を捨てる Python パッケージマネージャ PDM を試す
この記事は Sansan Advent Calendar 2022 19日目の記事です。
前日は fujisyo32 さんの
でした。
今年は特に画像周りで拡散モデルの話題で持ち切りでしたね。言語生成周りの研究も非常に興味深いです。
はじめに
私が所属する研究開発部では、Python のパッケージマネージャとして Poetry を標準的に利用しています。
Rust のように toml でパッケージを人間が認識しやすい形で管理できる点は非常に魅力的であり、setup.py, requirements.txt, setup.cfg, MANIFEST.in 等を代替できるため非常に便利です。
しかしながら最近、Poetry を用いたインストールやパッケージ追加等の依存解決に凄まじく時間を要しており、なんとか速度削減して開発のサイクルを早めることは出来ないかなと感じております。
そこで今回は、以前からあくまで個人的に試したいと思っていた高速なパッケージマネージャである PDM を試してみたいと思います。
PDM とは

PDM も Poetry と同様に pyproject.toml によってパッケージを管理する Python パッケージマネージャです。
Poetry との大きな差異としては、次の2点が挙げられます。
- PEP 582 に基づき、仮想環境を使わずに利用できる仕組みを搭載 (利用するかは選択可能)
- 依存解決を含めて、動作が非常に高速
一方で CLI ツールとしては Poetry と操作感が非常に似ており Poetry ユーザであれば簡単に利用することが可能です。早速試していきましょう。
PDM を試す
紹介時の PDM のバージョンは 2.3.3 です。
インストール
インストール方法は公式HP等を参照してください。よくある curl で持ってくるやつです。
$ curl -sSL https://raw.githubusercontent.com/pdm-project/pdm/main/install-pdm.py | python Installing PDM (2.3.3): Creating virtual environment Installing PDM (2.3.3): Installing PDM and dependencies Installing PDM (2.3.3): Making binary at /Users/nersonu/.local/bin Usage: pdm [-h] [-V] [-c CONFIG] [-v] [-I] [--pep582 [SHELL]] {add,build,cache,completion,config,export,import,info,init,install,list,lock,publish,remove,run,search,self,plugin,show,sync,update,use,venv} ... ____ ____ __ ___ / __ \/ __ \/ |/ / / /_/ / / / / /|_/ / / ____/ /_/ / / / / /_/ /_____/_/ /_/ Commands: {add,build,cache,completion,config,export,import,info,init,install,list,lock,publish,remove,run,search,self,plugin,show,sync,update,use,venv} add Add package(s) to pyproject.toml and install them build Build artifacts for distribution cache Control the caches of PDM completion Generate completion scripts for the given shell config Display the current configuration export Export the locked packages set to other formats import Import project metadata from other formats info Show the project information init Initialize a pyproject.toml for PDM install Install dependencies from lock file list List packages installed in the current working set lock Resolve and lock dependencies publish Build and publish the project to PyPI remove Remove packages from pyproject.toml run Run commands or scripts with local packages loaded search Search for PyPI packages self (plugin) Manage the PDM program itself (previously known as plugin) show Show the package information sync Synchronize the current working set with lock file update Update package(s) in pyproject.toml use Use the given python version or path as base interpreter venv Virtualenv management Options: -h, --help show this help message and exit -V, --version show the version and exit -c CONFIG, --config CONFIG Specify another config file path(env var: PDM_CONFIG_FILE) -v, --verbose -v for detailed output and -vv for more detailed -I, --ignore-python Ignore the Python path saved in the .pdm.toml config --pep582 [SHELL] Print the command line to be eval'd by the shell Successfully installed: PDM (2.3.3) at /Users/nersonu/.local/bin/pdm
PDM でプロジェクトを立ち上げる
プロジェクトのルートディレクトリで pdm init すれば、対話式でプロジェクトを立ち上げることが出来ます。
$ pdm init Creating a pyproject.toml for PDM... Please enter the Python interpreter to use 0. /Users/nersonu/.pyenv/shims/python3 (3.10) 1. /Users/nersonu/.pyenv/shims/python (3.10) 2. /Users/nersonu/.pyenv/versions/3.10.9/bin/python3.10 (3.10) 3. /Users/nersonu/.pyenv/shims/python3.10 (3.10) 4. /Users/nersonu/.pyenv/shims/python3.9 (3.9) 5. /usr/local/bin/python3.9 (3.9) 6. /Users/nersonu/.pyenv/versions/3.9.13/bin/python3.9 (3.9) 7. /usr/bin/python3 (3.8) 8. /usr/bin/python2.7 (2.7) 9. /Users/nersonu/Library/Application Support/pdm/venv/bin/python (3.10) Please select (0): 0 Using Python interpreter: /Users/nersonu/.pyenv/shims/python3 (3.10) Would you like to create a virtualenv with /Users/nersonu/.pyenv/versions/3.10.9/bin/python3? [y/n] (y): y Is the project a library that will be uploaded to PyPI [y/n] (n): n License(SPDX name) (MIT): Author name (nersonu): Author email (nersonu@gmail.com): Python requires('*' to allow any) (>=3.10): >=3.9 Changes are written to pyproject.toml. $ ls pyproject.toml
特徴的な点としては、利用する Python インタプリタを指定することです。
ここで指定したインタプリタは、.pdm.toml に書かれます。
[python] path = "/Users/nersonu/.pyenv/shims/python3"
なお、ユーザごとに利用するインタプリタが異なることから、このファイルは git などで commit しないように気をつけましょう。
また、 Poetry や Rust の Cargo のように src ディレクトリや README ファイルは生成されません。
生成された pyproject.toml はこのようになっています。
[tool.pdm]
[project]
name = ""
version = ""
description = ""
authors = [
{name = "nersonu", email = "nersonu@gmail.com"},
]
dependencies = []
requires-python = ">=3.9"
license = {text = "MIT"}
pyproject.toml の形式は PEP 621 に基づいており、Poetry とは若干形式が異っていますね。
仮想環境については、 pdm init の際に生成するようにした (以下)
Would you like to create a virtualenv with /Users/nersonu/.pyenv/versions/3.10.9/bin/python3? [y/n] (y): y
ため、pdm run でルートに作られた .venv を利用して実行することができます。
$ pdm run which python /Users/nersonu/workspace/try_pdm/init_pdm/.venv/bin/python
パッケージの追加
poetry add と同じような形で pdm add でパッケージの追加が可能です。
$ pdm add numpy pandas Adding packages to default dependencies: numpy, pandas 🔒 Lock successful Changes are written to pdm.lock. Changes are written to pyproject.toml. Synchronizing working set with lock file: 5 to add, 0 to update, 0 to remove ✔ Install six 1.16.0 successful ✔ Install python-dateutil 2.8.2 successful ✔ Install pytz 2022.7 successful ✔ Install pandas 1.5.2 successful ✔ Install numpy 1.23.5 successful 🎉 All complete! $ ls pdm.lock pyproject.toml
pdm.lock が生成され、poetry.lock と同様に依存関係等がここに残されます。
また、 pyproject.toml は以下のように更新されています。
[tool.pdm]
[project]
name = ""
version = ""
description = ""
authors = [
{name = "nersonu", email = "nersonu@gmail.com"},
]
dependencies = [
"numpy>=1.23.5",
"pandas>=1.5.2",
]
requires-python = ">=3.9"
license = {text = "MIT"}
Poetry と同様に、開発用ライブラリとライブラリのグループ管理が可能です。
Poetry と若干異なるところは、開発用ライブラリをグループと同様に依存関係に含めるか、独立させるかオプションの指定の仕方で選べるところです。
今回は依存関係に含めない形で、開発用ライブラリとして pytest をインストールする形を紹介します。
$ pdm add -d pytest Adding packages to dev dev-dependencies: pytest 🔒 Lock successful Changes are written to pdm.lock. Changes are written to pyproject.toml. Synchronizing working set with lock file: 7 to add, 0 to update, 0 to remove ✔ Install exceptiongroup 1.0.4 successful ✔ Install iniconfig 1.1.1 successful ✔ Install tomli 2.0.1 successful ✔ Install pluggy 1.0.0 successful ✔ Install packaging 22.0 successful ✔ Install attrs 22.1.0 successful ✔ Install pytest 7.2.0 successful 🎉 All complete!
pyproject.toml では tool.pdm.dev-dependencies の項に追加されています。
[tool.pdm]
[tool.pdm.dev-dependencies]
dev = [
"pytest>=7.2.0",
]
[project]
...
グループ追加 (ここでは "plot" という名前にしています) は以下のように行えます。
$ pdm add -G plot matplotlib seaborn Adding packages to plot dependencies: matplotlib, seaborn 🔒 Lock successful Changes are written to pdm.lock. Changes are written to pyproject.toml. Synchronizing working set with lock file: 13 to add, 0 to update, 0 to remove ✔ Install cycler 0.11.0 successful ✔ Install pyparsing 3.0.9 successful ✔ Install kiwisolver 1.4.4 successful ✔ Install contourpy 1.0.6 successful ✔ Install seaborn 0.12.1 successful ✔ Install fonttools 4.38.0 successful ✔ Install pillow 9.3.0 successful ✔ Install matplotlib 3.6.2 successful 🎉 All complete!
最終的な pyproject.toml は次のようになりました。
[tool.pdm]
[tool.pdm.dev-dependencies]
dev = [
"pytest>=7.2.0",
]
[project]
name = ""
version = ""
description = ""
authors = [
{name = "nersonu", email = "nersonu@gmail.com"},
]
dependencies = [
"numpy>=1.23.5",
"pandas>=1.5.2",
]
requires-python = ">=3.9"
license = {text = "MIT"}
[project.optional-dependencies]
plot = [
"matplotlib>=3.6.2",
"seaborn>=0.12.1",
]
なお、 project.optional-dependencies の中に dev を含めたい場合は -dG で出来るようです。
virtualenv との併用
pyenv local hoge のように、 pyenv や pyenv-virtualenv を利用している場合の挙動を確認しておきましょう。
$ pyenv local try_pdm $ pip -V pip 22.3.1 from /Users/nersonu/.pyenv/versions/3.10.9/envs/try_pdm/lib/python3.10/site-packages/pip (python 3.10)
試しに pdm init してみると、仮想環境を生成する質問がなくなり、生成されなくなりました。
$ pdm init Creating a pyproject.toml for PDM... Please enter the Python interpreter to use 0. /Users/nersonu/.pyenv/shims/python3 (3.10) 1. /Users/nersonu/.pyenv/shims/python (3.10) 2. /Users/nersonu/.pyenv/versions/3.10.9/bin/python3.10 (3.10) 3. /Users/nersonu/.pyenv/shims/python3.10 (3.10) 4. /Users/nersonu/.pyenv/shims/python3.9 (3.9) 5. /usr/local/bin/python3.9 (3.9) 6. /Users/nersonu/.pyenv/versions/3.9.13/bin/python3.9 (3.9) 7. /usr/bin/python3 (3.8) 8. /usr/bin/python2.7 (2.7) 9. /Users/nersonu/Library/Application Support/pdm/venv/bin/python (3.10) Please select (0): Using Python interpreter: /Users/nersonu/.pyenv/shims/python3 (3.10) Is the project a library that will be uploaded to PyPI [y/n] (n): License(SPDX name) (MIT): Author name (nersonu): Author email (nersonu@gmail.com): Python requires('*' to allow any) (>=3.10): >=3.9 Changes are written to pyproject.toml.
このまま pdm run でコマンド実行してみたところ、既に設定した仮想環境を利用できました。
既にプロジェクトで仮想環境が設定されている場合、認識して使ってくれるようですね。
PEP 582 の世界を体験する
PEP 582 とは
__pypackages__ というディレクトリをルートに置いておき、ここに保存されているパッケージを使おうという考えです。
こうすることで、仮想環境作ってそこでライブラリを入れて……という一連の流れをスキップ出来ます。
PEP 582 に対応しているツールはほとんどなく、PDM はこれを実現している希少なソフトウェアと言えるかもしれません。早速体験してみます。
PDM で PEP 582 の機能を有効にする
公式ページには、 bash でのやり方が載っていますが、自分は zsh を使っているので適当に .zshrc に突っ込んでみます。
$ pdm --pep582 >> ~/.zshrc $ exec $SHELL
プロジェクトを作ってみる
先に __pypackages__ ディレクトリを作っておきます。
$ mkdir __pypackages__
pdm init してみます。
pdm init Creating a pyproject.toml for PDM... Please enter the Python interpreter to use 0. /Users/nersonu/.pyenv/shims/python3 (3.10) 1. /Users/nersonu/.pyenv/shims/python (3.10) 2. /Users/nersonu/.pyenv/versions/3.10.9/bin/python3.10 (3.10) 3. /Users/nersonu/.pyenv/shims/python3.10 (3.10) 4. /Users/nersonu/.pyenv/shims/python3.9 (3.9) 5. /usr/local/bin/python3.9 (3.9) 6. /Users/nersonu/.pyenv/versions/3.9.13/bin/python3.9 (3.9) 7. /usr/bin/python3 (3.8) 8. /usr/bin/python2.7 (2.7) 9. /Users/nersonu/Library/Application Support/pdm/venv/bin/python (3.10) Please select (0): Using Python interpreter: /Users/nersonu/.pyenv/shims/python3 (3.10) Would you like to create a virtualenv with /Users/nersonu/.pyenv/versions/3.10.9/bin/python3? [y/n] (y): n You are using the PEP 582 mode, no virtualenv is created. For more info, please visit https://peps.python.org/pep-0582/ Is the project a library that will be uploaded to PyPI [y/n] (n): n License(SPDX name) (MIT): Author name (nersonu): Author email (nersonu@gmail.com): Python requires('*' to allow any) (>=3.10): Changes are written to pyproject.toml.
You are using the PEP 582 mode, no virtualenv is created.
For more info, please visit https://peps.python.org/pep-0582/
ちゃんと有効化されてそうです。試しに numpy でも追加してみましょう。
$ pdm add numpy Adding packages to default dependencies: numpy 🔒 Lock successful Changes are written to pdm.lock. Changes are written to pyproject.toml. Synchronizing working set with lock file: 1 to add, 0 to update, 0 to remove ✔ Install numpy 1.23.5 successful 🎉 All complete! ... $ tree -L 3 __pypackages__ __pypackages__ └── 3.10 ├── bin │ ├── f2py │ ├── f2py3 │ └── f2py3.10 ├── include └── lib ├── numpy └── numpy-1.23.5.dist-info
numpy が __pypackages__ 配下に入っていますね。面白い。
PEP 582 を実際に使用することはなかなか無いと思いますが、初学者にとって仮想環境に触れずに済むようなパッケージ管理は非常に魅力的です。 これを実現できる PDM なかなか良さげですね。
速度比較
前回の記事を流用します。実は、比較先の一番左が PDM でした。 nersonu.hatenablog.com
Python のパッケージマネージャの速度比較をしている Web ページから引用しています。画像は前2つは前回と同じです。


Poetry で一番ネックな部分である install 周りが超速いです。素晴らしいですね。
一方でパッケージの単純追加は Poetry に負けています (これだけ Poetry 1.3.1)。
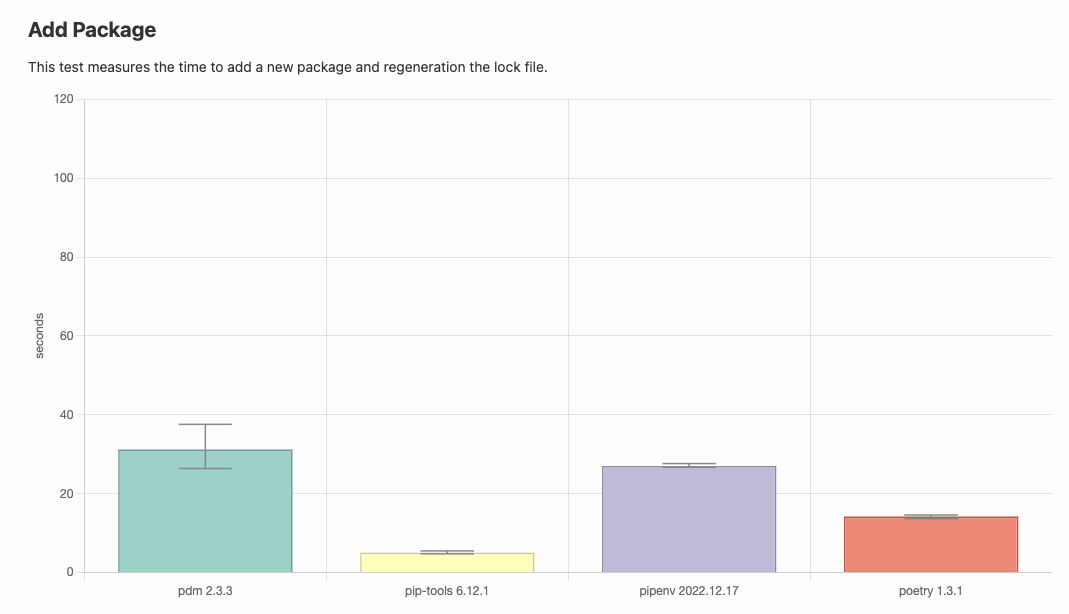
poetry install がとてつもなく時間がかかるため、こういった点は PDM に軍配が上がるんだろうなと感じています。
おわりに
今回は PDM を試しましたが、なかなか面白く、高速で良い感じでした。 いつか機会があれば業務でも導入してみたいですね。
明日は id:kur0cky さんです。皆様、よいクリスマスを。
Poetry 1.3.0 がリリースされたよ
この記事は whywaita Advent Calendar 2022 11日目の記事です。
前日は id:hinananoha さんの
でした。壊れると悲しいですよね。
ということで、今回は whywaita さんでなにかするネタが思いつかなかったため、よく壊れる Python のパッケージマネージャ Poetry の最新バージョンについて書こうと思います。
Poetry とは
Poetry は Python のパッケージマネージャで、 requirements.txt や setup.py を代替していい感じにパッケージングしたり toml ベースでわかりやすくライブラリ管理できるソフトウェアです。
ぼくと Poetry
9月頃、1.2.0 がリリースされました。

公式のアナウンスでは 1.1.x と 1.2.x 系で互換があるとのことでしたが、壊れてしまい、社内でキレていました。
1.3.0 リリース 🎉
2022年12月9日、1.3.0 がリリースされました。(そのぼくがキレていた Issue は解決していませんが、特にキレてはないです)
1.2 では git 経由のインストールで subdirectory オプションが使えるようになったり*1、pyproject.toml のグループ機能が拡充されたりと個人的にかなり楽しみな機能追加が多くありました。
今回は特に個人的に楽しみなアップデートは無いので、さらっと気になったものだけさらっていこうと思います。
作業ディレクトリを CLI のオプションで指定可能に
-C, -directory で作業ディレクトリを指定することが、CLI 上で出来るようになりました。
$ poetry install -C python_workspace/
poetry.lock のフォーマットが変更に
Poetry 1.2.2 は 1.3 のフォーマットを読めるとかなんとからしいです。 試しに以下のパッケージを追加したもので、1.2.2 と 1.3 で diff をとってみましたが、よくわかりませんでした。
$ poetry add numpy pandas matplotlib Using version ^1.23.5 for numpy Using version ^1.5.2 for pandas Using version ^3.6.2 for matplotlib
@generated で、自動生成を示す説明が付いているところは、今回の追加機能を反映されているものでしょう。
速度
Poetry は以下のような Issue が立つほどユーザが速度改善を望んでいます。
今回 poetry update や poetry lock の挙動やキャッシュ周りに修正が入っているらしいので、Python のパッケージマネージャの速度比較をしている Web ページを見ながら、速度の影響が出ているのか少し見てみましょう。
一番利用する poetry install の時間がさらにかかっていそうでかなり厳しいものがありますね。
さいごに
なんやかんや言いつつも、管理が大変な requirements.txt や黒魔術のような setup.py にはもう戻りたくないため、 Poetry には今後もお世話になることと思います。
あと来年は whywaita さんをネタに出来るように、なにか考えていこうと思います。
明日は id:kyontan2 さんです。
*1:インストールしたい先の社内ライブラリがモノレポ構成とかだと特に助かった